第13章:半监督学习 — 西瓜书学习笔记
本文是周志华《机器学习》(西瓜书)第13章 半监督学习(Semi-Supervised)的学习笔记,涵盖本章所有核心知识点,配有通俗类比与公式推导。 ①. 问题概述与基本假设为什么半监督学习有效?三大核心假设 🎓 生活类比:考前临时抱佛脚 期末复习只有 10 道有答案的例题(标注数据),但你手里有 1000 份历年试卷但没有答案(无标签数据)。半监督学习就是:虽然不知道 1000 份的答案,但通过观察这些题目的规律和分布——“这类题总是一起出现”、”这两道题很像”——来辅助你学习那 10 道有答案的题,效果远好于只看 10 道题。 📌 问题设定 设有有标记样本集 Dl={(x1,y1),…,(xl,yl)}D_l = \{(\boldsymbol{x}_1, y_1), \ldots, (\boldsymbol{x}_l, y_l)\}Dl={(x1,y1),…,(xl,yl)},以及无标记样本集 Du={xl+1,…,xl+u}D_u = \{\boldsymbol{x}_{l+1}, \ldots, \boldsymbol{x}_{l+u}\}Du={...
第14章:概率图模型 — 西瓜书学习笔记
本文是周志华《机器学习》(西瓜书)第14章 概率图模型(Probabilistic Graphical)的学习笔记,涵盖本章所有核心知识点,配有通俗类比与公式推导。 ①. 基本概念与模型分类有向图 vs. 无向图,概率图的两种范式 🗺️ 生活类比:家族族谱 vs. 朋友圈 **有向图(贝叶斯网络)**像家族族谱——你从父母到子女有明确的方向。”基因”沿有向边传递,父子关系带来因果依赖。**无向图(马尔可夫随机场)**像朋友圈——朋友之间没有方向,你们相互影响。”状态”通过无向连接相互约束。 📐 概率图模型 = 图结构 + 概率分布 一个概率图模型就是用图 G=(V,E)\mathcal{G}=(\mathcal{V},\mathcal{E})G=(V,E) 描述随机变量集合 X={X1,…,Xn}\boldsymbol{X}=\{X_1,\ldots,X_n\}X={X1,…,Xn} 之间的依赖关系,用一套参数 Θ\boldsymbol{\Theta}Θ 来量化这些关系。 有向图(贝叶斯网络) A B C D 父→子 局部条件概率表(CPT)...
第15章:规则学习 — 西瓜书学习笔记
本文是周志华《机器学习》(西瓜书)第15章 规则学习(Rule Learning)的学习笔记,涵盖本章所有核心知识点,配有通俗类比与公式推导。 ①. 基本概念与”规则”的形式命题规则 vs. 一阶规则,规则集与规则列表 📋 生活类比:医学诊断手册 医生看病的经验,最自然的表达就是”规则”——“如果发烧+咳嗽+白细胞升高,则很可能是细菌感染”。一条规则覆盖一类病例,不需要算概率,不需要调参数,看一眼就懂。规则学习的目标就是从数据中自动挖掘这样的诊断规则。 📜 规则的基本形式 规则的一般形式为: 📐 命题规则(Propositional Rule) IF (f1∈V1)∧(f2∈V2)∧⋯∧(fk∈Vk) THEN c \textbf{IF}\;(f_1 \in V_1) \land (f_2 \in V_2) \land \cdots \land (f_k \in V_k)\;\textbf{THEN}\; c IF(f1∈V1)∧(f2∈V2)∧⋯∧(fk∈Vk)THENc 规则体(body)是属性-值检验的合取,头部(head)是一个类别标...
第16章:强化学习 — 西瓜书学习笔记
本文是周志华《机器学习》(西瓜书)第16章 强化学习(Reinforcement Learning)的学习笔记,涵盖本章所有核心知识点,配有通俗类比与公式推导。 ①. 任务与框架:MDP马尔可夫决策过程:状态、动作、奖励、转移 🐕 生活类比:训狗学把戏 你不直接告诉狗狗”坐下”的精确肌肉指令,你只在它做对时给一根骨头(奖励),做错时不给。狗狗试了无数次后才隐约明白”哪种行为更容易拿到骨头”。它不知道全局最优策略是什么,只能在试错中逐渐逼近。 🎮 MDP 四要素 智能体 (Agent) 策略 π 环境 (Environment) 动态 P,R 动作 a_t 新状态 s_{t+1} + 奖励 r_t 要素 符号 含义 状态空间 S\mathcal{S}S 所有可能的环境状态 动作空间 A\mathcal{A}A 智能体可执行的动作 状态转移概率 P(s′∣s,a)P(s'|s,a)P(s′∣s,a) 在状态 sss 执行 aaa 后转移到 s′s's′ 的概率 奖励函数 R(s,a)R(s,a)R(s...
第10章:降维与度量学习 — 西瓜书学习笔记
本文是周志华《机器学习》(西瓜书)第10章 降维与度量学习(Dimensionality Reduction)的学习笔记,涵盖本章所有核心知识点,配有通俗类比与公式推导。 01. k 近邻学习(kNN)最简单的”懒惰学习”算法 🔢 核心思想 **k近邻学习(k-Nearest Neighbor,kNN)是一种懒惰学习(lazy learning)**算法——它不构建显式的模型,而是在预测时直接找到训练集中最近的 kkk 个样本,用它们的标记来决策。 🍎 通俗理解 你搬到一个新城市,不知道周围的餐厅好不好吃。怎么判断?看最近的几家邻居餐厅的口碑——大家都说好,这家大概也不错。这就是 kNN 的逻辑:我不认识你,但我知道你的邻居,通过邻居来判断你。 📐 kNN 分类规则 给定测试样本 xxx,找其最近的 kkk 个训练样本构成集合 Nk(x)N_k(x)Nk(x),通过投票决定类别: y^=argmaxc∈Y∑xi∈Nk(x)1(yi=c) \hat{y} = \underset{c \in \mathcal{Y} }{\arg\max} \sum_{x_i ...
第11章:特征选择与稀疏学习 — 西瓜书学习笔记
本文是周志华《机器学习》(西瓜书)第11章 特征选择与稀疏学习(Feature Selection)的学习笔记,涵盖本章所有核心知识点,配有通俗类比与公式推导。 01. 特征选择概述为什么需要选特征? 🎯 特征选择的目的 现实数据集中往往包含成百上千个特征,但并非所有特征都对学习有用。特征可分为三类: ✅ 相关特征 对当前学习任务有用的特征,应当保留。 ❌ 无关特征 与学习任务无关(不相关特征),应当删除。 ⚠️ 冗余特征 包含的信息可由其他特征推出(多余),可以删除但有时有辅助作用。 🍎 通俗理解 你要根据一个人的信息预测他的收入:✅ 相关特征:学历、工作年限、所在城市——明显有用❌ 无关特征:鞋码、头发颜色——基本没用⚠️ 冗余特征:月薪和年薪——一个可以由另一个算出来 特征选择就是保留相关特征,删除无关和冗余特征,让模型更高效准确。 🔑 特征选择 vs 降维 特征选择:从原始特征中挑选出一个子集,特征的含义不变 降维(如PCA):将原始特征变换为新的低维特征(如主成分),失去原始含义 两者都能减少特征维度,但特征选择保留了可解释性 🎯 三...
第12章:计算学习理论 — 西瓜书学习笔记
本文是周志华《机器学习》(西瓜书)第12章 计算学习理论(Learning Theory)的学习笔记,涵盖本章所有核心知识点,配有通俗类比与公式推导。 01. 基础知识与符号学习理论的基本概念和数学工具 🧮 核心概念 📐 基本设置 X\mathcal{X}X:样本空间,Y\mathcal{Y}Y:标记空间(如 {−1,+1}\{-1,+1\}{−1,+1}) D\mathcal{D}D:X×Y\mathcal{X} \times \mathcal{Y}X×Y 上的未知分布 D={(x1,y1),…,(xm,ym)}D = \{(x_1,y_1),\ldots,(x_m,y_m)\}D={(x1,y1),…,(xm,ym)}:从 D\mathcal{D}D 独立同分布采样的训练集 h:X→Yh: \mathcal{X} \to \mathcal{Y}h:X→Y:假设(即学到的分类器) H\mathcal{H}H:假设空间(所有候选假设的集合) 📐 误差的定义 泛化误差(真实误差): E(h;D)=P(x,y)∼D[h(x)≠y]E(h;\mathca...

电控组考核
题目一 选择题1.若用数组名作为函数调用的实参,传递给形参的是( )A.数组的首地址B.数组第一个元素的值C.数组中全部元素的值D.数组元素的个数 2.使用值传递方式将实参传给形参,下列说法正确的是( )A.形参是实参的备份B.实参是形参的备份C.形参和实参是同一对象D.形参和实参无联系 3.以下说法正确的是( )A.下列函数调用语句中含有2个实参:fun((a1,a2),(a3,a4,a5));B.在函数中未指定存储类别的变量,其隐含的存储类别是void类型C.若调用一个函数,且此函数中没有return语句,则该函数没有返回值D.全局变量的作用域一定比局部变量的作用域范围大 4.以下说法错误的是( )A.continue语句只能用于循环语句中B.在分支结构switch中,case后面跟的一定是常量C.在不同函数中可以使用相同名字的变量D.int num[3]={1,2,3},使用num++来让数组下标后移 5.char ch[]="abcd"在内存中所占的字节数是()A.4B.5C.8D.10 6.该程序段输出结果为() 12int matrix...

生产者与消费者模型
多线程编程的一个经典模型 一、生产者与消费者模型生产者与消费者模型(Producer - Consumer Model)是一种经典的多线程同步问题模型,用于描述生产者和消费者之间对共享资源(如缓冲区)的交互过程。它在计算机科学中被广泛应用于解决多线程编程中的线程同步、资源竞争和数据共享等问题。 (一)模型的基本组成 生产者(Producer) 生产者的作用是生成数据并将其放入共享缓冲区。生产者不断地生产数据,例如在实际应用场景中,它可以是一个数据采集线程,从传感器采集数据后放入缓冲区。 消费者(Consumer) 消费者从共享缓冲区中取出数据并进行处理。消费者不断地消费数据,比如一个数据分析线程从缓冲区取出数据进行分析处理。 共享缓冲区(Shared Buffer) 这是生产者和消费者之间共享的资源。它可以是一个队列、数组或其他数据结构。缓冲区的大小是有限的,它存储着生产者生产的、尚未被消费者消费的数据。 (二)模型的核心问题 同步问题 生产者和消费者需要协调工作。如果缓冲区满了,生产者不能继续生产,否则会导致数据丢失或覆盖;如果缓冲区空了,消费者不能继续消...
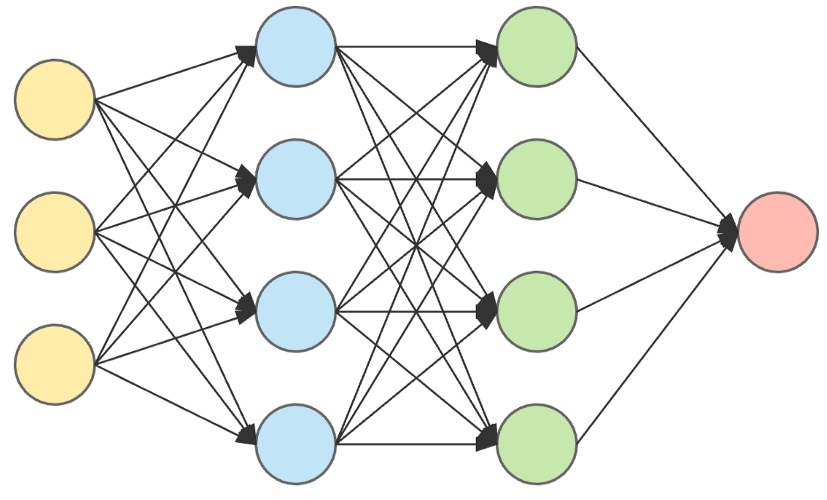
感知机
简单介绍一下感知机 1.1 感知机的概念1.1.1 什么是感知机?**感知机(Perceptron)**是Frank Rosenblatt在1957年提出的一种人工神经网络模型,是最简单的前馈神经网络,也是二元线性分类器的基础。它被视为单层神经网络的雏形,为后续更复杂的模型(如多层感知机、支持向量机等)奠定了基础。 1.1.2 特点优点: 它能够接受多个信号,输出一个信号。 简单、计算高效。 可处理线性可分问题(如与门、非与门、或门)。 局限性: 无法解决非线性可分问题(如异或门),这一缺陷导致了神经网络的第一次低谷,直到多层感知机(MLP)和非线性激活函数的引入。 对噪声和异常值敏感。 1.1.3 基本原理感知机模拟生物神经元的工作方式: 输入:接收多个特征信号((x_1, x_2, …, x_n))。 加权求和:对输入信号赋予权重((w_1, w_2, …, w_n)),计算加权和 (z = \sum_{i=1}^n w_i x_i + b)((b)为偏置项)。 节点计算传送过来的信号的总和,只有当这个总和超过某个阈值时才会输出1。权重越大,对应该权重的...