第5章:神经网络 — 西瓜书学习笔记
本文是周志华《机器学习》(西瓜书)第5章 神经网络(Neural Networks)的学习笔记,涵盖本章所有核心知识点,配有通俗类比与公式推导。
1神经元模型
M-P 神经元
神经网络的基本单元模拟了生物神经元:接收多个输入信号,加权求和,经激活函数后输出。
📐 公式
其中 为激活函数, 为偏置阈值。
常用激活函数
| 函数 | 表达式 | 特点 |
|---|---|---|
| Sigmoid | 输出 (0,1),梯度饱和问题 | |
| Tanh | 输出 (-1,1),零中心,仍有饱和 | |
| ReLU | 缓解梯度消失,计算简单,但”死神经元”问题 | |
| LeakyReLU | 解决死神经元, 通常很小 |
🍉 通俗类比
一个神经元就像公司里的决策者:听取各个下属(输入)的汇报,每个人说话分量不同(权重 ),最后自己有一个判断门槛(阈值 )。超过门槛就拍板”通过”(激活),没超过就”搁置”(不激活)。
2感知机与多层网络
感知机(Perceptron)
最简单的神经网络:两层结构,输入层 + 输出层。激活函数为阶跃函数。只能解决线性可分问题(如 AND、OR,解决不了 XOR)。
📐 公式
⚠️ 注意事项
感知机局限性:Minsky & Papert 1969 年证明单层感知机连 XOR 都解不了,直接导致了第一次”AI 寒冬”。但多加一层就解决了——这正是多层网络的意义!
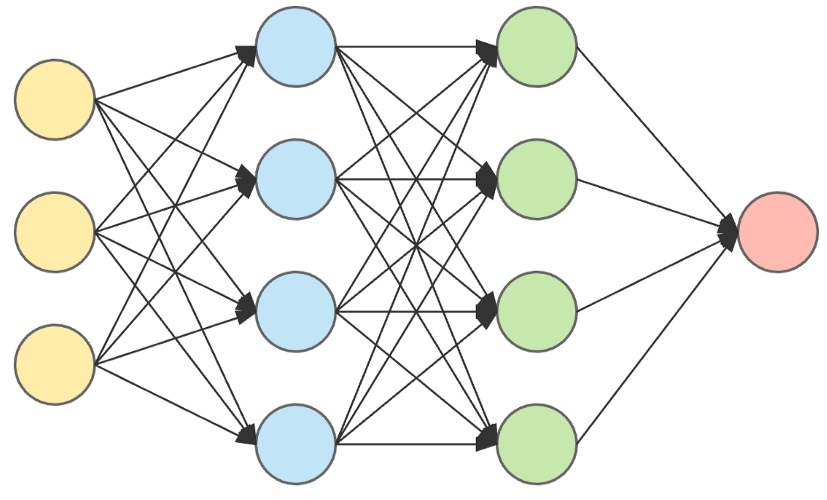
多层前馈网络
将多个神经元分层连接:输入层、隐层(可多个)、输出层。每层神经元与下一层全连接,没有同层或跨层连接。
📌 核心定义
万能近似定理:只要隐层神经元足够多,具有单个隐层的前馈网络就能以任意精度逼近任意连续函数。这给了多层网络理论上的底气。
3BP 算法(误差逆传播)
BP(BackPropagation)是训练多层网络的核心算法,它解决了”隐层没有监督信号”的难题:将输出层的误差沿网络反向传播,逐层更新权重。
**算法:标准 BP(随机梯度下降)** 1. 前向传播:计算每层输出,直到得到最终预测 2. 计算输出层误差梯度 3. 反向传播:利用链式法则逐层回传梯度 4. 更新权重:w ← w - η · ∂E/∂w 5. 对所有样本重复,直到收敛核心公式(链式法则):
δ_j = f’(net_j) · Σ_k (w_{kj} · δ_k) — 隐层误差
Δw_{ij} = η · δ_j · x_i — 权重更新
🍉 通俗类比
BP 算法像乐团排练。先让乐团(网络)演奏一遍(前向传播),指挥听出错在哪(计算误差),然后从最后排的乐手(输出层)往前,依次告诉每个人”你这个音高了半拍”(反向传播梯度),大家各自调整(更新权重)。
标准 BP vs 累积 BP
| 标准 BP | 累积 BP | |
|---|---|---|
| 更新频率 | 每个样本更新一次 | 读完整个训练集(一轮)更新一次 |
| 速度 | 更快退出 | 更准确的梯度方向 |
| 参数调整 | 需要更多轮次 | 达到同样精度时轮次更少 |
4全局最小与局部极小
神经网络的损失函数非凸,梯度下降容易卡在局部极小值。
跳出局部极小的策略
| 策略 | 思路 | 典型方法 |
|---|---|---|
| 多组初始参数 | 多跑几次,取最佳结果 | Random Restart |
| 模拟退火 | 以一定概率接受更差的解,概率随”温度”下降 | SA |
| 随机梯度下降 | 梯度本身带噪声,有助跳出(SGD 的隐藏优势!) | SGD |
| 动量 | 积累历史梯度,像惯性冲过局部极小 | Momentum, Adam |
5其他常见神经网络
| 网络 | 核心思想 | 特点 |
|---|---|---|
| RBF 网络 | 隐层用径向基函数(如高斯)激活 | 单隐层,局部逼近,训练快 |
| ART 网络 | 自适应谐振理论,竞争学习 | 可增量学习,不遗忘旧知识 |
| SOM 网络 | 自组织映射,竞争型网络 | 无监督降维/可视化,保持拓扑结构 |
| 级联相关网络 | 自适应地增加隐层神经元 | 结构自学习,训练时固定已有权重 |
| Elman 网络 | 最简单的递归神经网络(RNN) | 隐层输出反馈给输入,有记忆能力 |
| Boltzmann 机 | 基于能量的随机网络 | 受限版本 RBM 是 DBN 的基础 |
🍉 通俗类比
这六种网络是上世纪八九十年代的”神经动物园”。SOM 像一个自动地图绘制员——把高维数据拍到二维平面上,且相似的东西放在相近位置。Elman 网络则是有记忆的秘书——会把上次处理的上下文带到下一次。
6深度学习
典型深度学习模型 = 多层网络 + “逐层预训练” + “微调”。核心挑战:
- 计算能力:大规模 GPU 并行
- 训练数据:大数据时代解决了数据饥渴
- 训练技巧:ReLU + BatchNorm + Dropout + 预训练
💡 技巧提示
西瓜书中深度学习部分强调了**逐层预训练(layer-wise pre-training)**这一关键思想:先用无监督学习逐层训练(如用 RBM 堆叠成 DBN),再把整个网络当作普通多层网络用 BP 微调。这个技巧打破了深层网络难以训练的困局。
7本章总结
📝 考试高频考点
- 感知机局限:不能解决 XOR 等线性不可分问题
- BP 算法的链式法则推导(隐层误差的反向传播公式)
- 标准 BP vs 累积 BP的权衡
- 为什么神经网络的损失函数是非凸的,以及三种跳出局部极小的方法
- Sigmoid 梯度消失问题及其解决方案(ReLU)
- 万能近似定理的含义
📌 核心定义
一句话总结:神经网络 = 多层神经元链式堆叠 + 反向传播训练。本章内容是一切深度学习的基础——CNN、RNN、Transformer 本质上都是在此框架上添加了特定结构。